BOV has a problem – Revolut is seriously eating through its card payments business (and profits). Revolut in Malta is very famous and for a very good reason. No, it’s not because it provides free, VISA / Chip / Contactless cards; BOV does that as well. It’s because Revolut’s mobile app is just awesome. BOV seems to (finally) notice this and they have Revolut at their sights. How can BOV one-up Revolut? Tap-to-pay purchases!
BOV have been working on their now BOV PAY app – this will enable a mobile user to make purchases by tapping their phones. Mobile vendors have already developed this though; the likes of Google Pay, Apple Pay, Samsung Pay already exist. But here’s the problem – in Malta, only Apple Pay is officially supported, so non-android users are hung out to dry (unless you follow my unofficial guide here)
Smartly enough, BOV prioritized launching an app for Android firstly. The reason is simple – since there is no official tap-to-pay application in Malta, they’re tapping (pun intended) into an untapped market. So, android users, rejoice!..or should we?
You see, the application is in a very early phase; I’d say it’s just an MVP. The application is sluggish, the user experience is quite rubbish and the app is riddled with bugs. Tap-to-pay works, but the experience is frankly rubbish. Once I tapped my phone to pay, the app took more than 5 seconds to simply show the BOV screen and the card that I’ve paid with. But alas, it works.
Let’s discuss the next most infuriating thing. Honestly, once they get this (properly) working, I’ll seriously consider switching back to use BOV cards instead of Revolut cards daily. There is NO WAY to INSTANTLY see the transactions that I’ve affected!
Well, firstly, the new BOV PAY app does not show any transaction whatsoever. I’m guessing that this is a work in progress, and I should be using the older app to check the transaction. OK, fine. But, still, the old app does not enable me to INSTANTLY see my transaction. I’m able to see that there is a difference between book balance and available balance, but the transaction does not show up. This is PAINFUL – show me that I’ve made a payment, even though the payment may be reverted if unclaimed by merchant. It’s my right to see where my money went! UGH!
Anyway, let’s dive into some other criticism about the app; in no order:
- It takes at least 5 seconds to get the BOV logo and the loading spinner
- It takes another 5 seconds (or more) from successfully recognising my fingerprint into the main menu
- I had to add all my personal details and sign up. Why did I had to provide my name, address and other information? Can’t this be derived from ownership of the card? Or maybe through the authentication of the classic BOV app?
- When I press back, I prompted to log out; why? Isn’t it obvious that I’m the only person who’s using this app? Logout should be buried somewhere; I don’t need to see it every time.
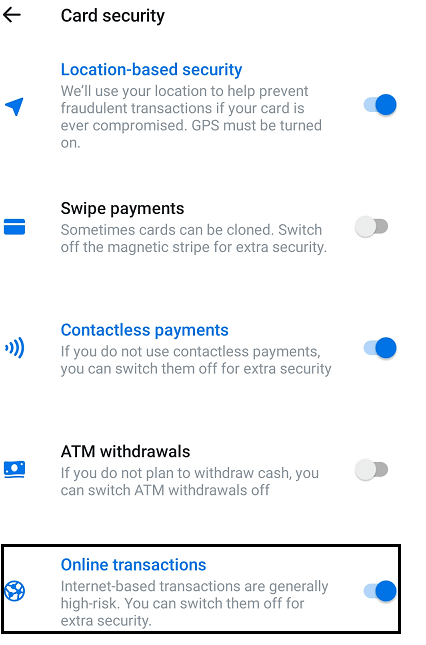
- The card controls feature is very weak – it only has ONE option. I’m guessing that this is WIP – no harm, no foul.
- Again, I’m not sure why through the Review Card Details I’m able to edit information such as the expiry date, CVV, address. This needs to be done the other way round; I’d prove who I am and cards are added automagically for me and the relevant information is obtained from your records. This is a VERY WEIRD feature.
- From a UI Experience. why does load the picture of the card each time? I’m always looking at a spinner before the card image is displayed.
- Expiring sessions? Really? What’s protecting me from? As soon as the app is dismissed, THEN and only THEN the session should be terminated.
- The locator feature; I’m assuming that this shows a list of ATMS? Poor naming?
- The setting section looks very basic; but I guess it gets the job done. OK
- The about us is very cheeky feature; it’s just a WebView of the BOV Site. Lazy!
- Tutorials
- The Pay-In-Site is a good and easy tutorial; the button to go to the cards section doesn’t work.
- Using the App is again, a WebView of the BOV site.
- Contact us – again, WebView.
- Terms and Privacy – All WebViews (oh, did I mention that the site is NOT mobile friendly?)
I also must mention the fact that I’ve forwarded much of the feedback to BOV and they instantly got back to me over the phone to listen to my feedback. I must give credit where it’s due. I’m hoping that they the feedback that the clients are giving to them so that they can create an awesome app.
They’ve started on the right track, but they got so much progress to do. I’m just hoping that eventually they’ll introduce the Google Pay integration. But this will have to do for now. I’ll be sticking to my Google Pay and Revolut combination though; it works great.
EDIT – Here’s a demo of the BOV PAY in real life – note how long it takes for the BOV APP to trigger (and show up) after payment takes place.