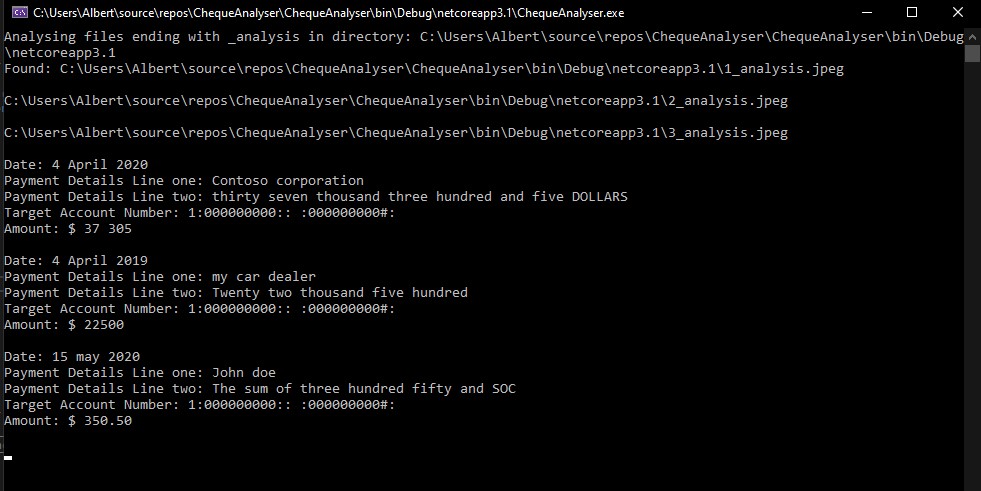
Just to get this out of the way, you might find conflicting information on the internet saying that now, Kafka doesn’t require a Zookeeper installation, referred to as KRaft. As of time of writing, KRaft was just marked production ready just a month ago. At this point I still think that it might be a bit too early to adopt, especially given that tools to support KRaft may be immature. Confluent still marks KRaft as early access. So, let’s focus on a Kafka with Zookeeper.
What is Zookeeper? It is a tool which end products may use; on its own it doesn’t really do much. If your product requires distributed coordination while being highly reliable, then Zookeeper is a great product. In fact, therefore Kafka uses it. Kafka uses Zookeeper to hold multiple data structures, such as:
- The alive brokers
- Topic Configuration
- In-Sync Replicas
- Topic Assignments
- Quotas
Truth be told, you should not be super concerned on how they work in the background; this is just information that Kafka stores to remain functional. The main takeaway is that these are all decisions that need to be co-ordinated across a cluster, which Zookeeper does on behalf of Kafka.
So, let’s dive into why I’m writing the article in the first place. Production-worthy Zookeeper should not be a single node; it should be a cluster of nodes, referred to as an Ensemble. For an Ensemble to be healthy, it requires the majority (over 50%) of the servers to be online and communicating with each other. The majority is also referred to as a Quorum. Refer to this guide for more information – https://zookeeper.apache.org/doc/r3.4.10/zookeeperAdmin.html
Online, you’ll find this magic formula – 2xF + 1. The F in this case refers to how many servers you tolerate to have offline to remain functional.
If, for example, you don’t tolerate any servers to be offline to remain functional, 2×0 + 1 = 1 – you only need one server. But this means you can never ever afford a failure, which isn’t good. So, we’re not going to even consider that.
3 Server Ensemble
Let’s try it with tolerating one offline server – 2×1 + 1 = 3. Therefore, the Ensemble size should be 3 servers, to allow one failure. In fact, this is what you’ll find online – a minimum of three servers. At face value, it might look OK, but I believe it’s just a ticking timebomb.
When everything is healthy, the ensemble will look like the below.

When a node goes down, the ensemble will look like the below. It will still function, but cannot tolerate any more losses.

If a network split happens, or another node goes offline, a Quorum cannot be formed, hence it goes offline and intervention is needed.

You might say, tolerating one failure sounds GREAT. But, I’d say is far more than enough. Let’s face it, servers will need to be patched and this happens often. What happens if patching fails (or takes an awfully long time), and other server happens to suffer from some failure? You may say that this is highly unlikely to happen, but recently I just witnessed a server that took almost a day to be patched, fixed and brought back online. If, during that time, a blip happened in the network, the two servers would disconnect and would never manage to come back online, because of the Split Brain problem – https://en.wikipedia.org/wiki/Split-brain_(computing)
In my opinion, there will be times where you will operate with one node down, whether it would be patching or the bare metal suffers some problem, therefore 3 nodes aren’t enough.
5 Server Ensemble
Here’s what I think is a TRUE minimum – allowing 2 nodes to fail before going offline. To allow for two nodes, using the previous formula: 2×2 + 1 = 5. Therefore, the Ensemble size should be 5 servers, to allow for two failures.
When everything is healthy, the ensemble will look like the below.

When a node goes down, the ensemble will look like the below. It will still function and we can tolerate another loss.

When another node goes down, the ensemble will look like the below. It will still function, but cannot tolerate any more losses.

With 3 nodes down, less than 50% of the nodes are available, hence a Quorum cannot be formed.

You can also get taken offline with an offline node and a split network.

With a 5 server ensemble, if you are doing maintenance on a particular node, you still afford to lose another node before the ensemble is taken offline. Of course, this still suffers from the split brain problem, where if your 5 server ensemble suffers an offline node and gets a network split, directly in the middle. You’d end up with 2 nodes on each split and unable to serve any requests. Great care will need to be taken on which part of a data centre the servers are provisioned on.
This scaling can continue going upwards e.g. 7 node cluster. Of course at that point, you’ll need to factor in the higher latency that it brings (because more nodes will need to acknowledge messages) and the overall maintenance required. I’ve also omitted discussing the correct placement of availability zones for each server node. Great care must also be taken when doing so.
Until the next one!