Recently, I was working on a task where we had to get file entries and names off ZIP files stored on Azure. We had terabytes of data to go through and downloading them was not really an option. In the end of the day, we solved this in a totally different way, but I remained curious if this is possible, and it sure is.
The aim is to get all the entry names of ZIP files stored on an Azure Storage Account. Unfortunately, using our beloved HttpClient isn’t possible (or at least, I didn’t research enough). The reason is that although HttpClient does allow us to access an HttpRequest as a Stream, the Stream itself isn’t seekable (CanSeek: false).
This is why we need to use the Azure.Storage.Blobs API – this allows us to get a Seekable Stream against a File stored in Azure Storage Account. What this means is that we can download specific parts of the ZIP file where the names are stored, rather than the data itself. Here is a detailed diagram on how ZIP files are stored, though this is not needed as the libraries will handle all the heavy lifting for us – The structure of a PKZip file (jmu.edu)
We will also be using the out-of-the-box ZipArchive library. This will allow us to open a Zip File from a Stream. This library is also smart enough to know that if a stream is Seekable, it will seek to the part where the File Names are being stored rather than downloading the whole file.
Therefore, all we need is to open a stream to the ZIP using the Azure.Storage.Blobs, pass it to the ZipArchive library and read the entries out of it. This process ends up essentially almost instant, even for large ZIP files.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
In this series of posts, we’re investigating micro-optimizations in C#. As previously mentioned, these may not be applicable to all; but it’s still fun looking at these concepts.
Passing structs by ref brings a major disadvantage – the callee might mutate the value of the struct without the caller ever knowing. What if we need to pass structs in an efficient manner, whilst having peace of mind that the callee doesn’t mutate the struct?
Meet the in parameter modifier- C# 7.2
What does the in parameter modifier do? It allows us to pass the argument by reference and giving us the guarantee that the arguments cannot be modified by the callee. Excellent! Let’s run a quick test and make sure our performance is still comparable when passing by ref. Let’s have a struct with 2 properties – let’s have some work done using two different methods – passing by ref and passing by in.
public class SixteenBitStructBenchmark
{
[Benchmark]
[Arguments(100000000)]
public void BenchmarkIncrementByRef(int limit)
{
SixteenBitStruct sixteenBitStruct = new SixteenBitStruct();
int counter = 0;
do
{
IncrementByRef(ref sixteenBitStruct);
counter++;
}
while (limit != counter);
}
[Benchmark]
[Arguments(100000000)]
public void BenchmarkIncrementByIn(int limit)
{
SixteenBitStruct sixteenBitStruct = new SixteenBitStruct();
int counter = 0;
do
{
IncrementIn(sixteenBitStruct);
counter++;
}
while (limit != counter);
}
private void IncrementByRef(ref SixteenBitStruct sixteenBitStruct)
{
double sum = sixteenBitStruct.D1 + sixteenBitStruct.D2;
}
private void IncrementIn(in SixteenBitStruct sixteenBitStruct)
{
double sum2 = sixteenBitStruct.D1 + sixteenBitStruct.D2;
}
}
public struct SixteenBitStruct
{
public double D1 { get; }
public double D2 { get; }
}
Let’s see how they perform.
Method
limit
Mean
Error
StdDev
BenchmarkIncrementByRef
100000000
23.83 ms
0.0272 ms
0.0241 ms
BenchmarkIncrementByIn
100000000
238.21 ms
0.3108 ms
0.2755 ms
Performance loss?
Wait a second – why is IncrementByIn 10x slower than IncrementByRef when we’re accessing 2 properties in the same struct? Let’s have a look at the generated IL.
IncrementByRef
IL_0000: ldarg.1
IL_0001: call instance float64 InOperator.SixteenBitStruct::get_D1()
# Loads argument 1 (SixteenBitStruct) and call the getter
IncrementByIn
IL_0000: ldarg.1
# Prepare a new local variable on the evaluation stack
IL_0001: ldobj InOperator.SixteenBitStruct
# Copies the value of SixteenBitStruct into the loaed argument variable
IL_0006: stloc.0
IL_0007: ldloca.s V_0
IL_0009: call instance float64 InOperator.SixteenBitStruct::get_D1()
# Pops the newly created argument into location 0, loads local variable 0 (new copy of SixteenBitStruct) and call the getter
Interesting! When we’ve called the method by ref, the resultant IL just loads the argument and calls the getter. When we’ve called the method by in, the resultant IL creates a copy of the struct before the getter is called. It seems that each time we’re referencing the property, C# is generating a copy of the object for us? We’re facing a by-design feature – a defensive copy.
Why do we encounter a defensive copy?
When calling the getter of our properties, the compiler doesn’t know if the getter mutates the object. Although this is a getter, it’s only by convention that changes aren’t made; there is no language construct that prevents us from changing values in our getter. The compiler must honor the in keyword and generate a defensive copy, just in case the getter modifies the struct.
In the end of the day, a getter is just syntactic sugar for a method. Of course, defensive copies will be generated if methods are called on the struct since the compiles can’t provide any guarantee that the method call won’t mutate the struct.
How do we get around this?
We’ll need instruct the compiler that our struct is immutable, so the compiler doesn’t need to worry about creating defensive copies since values cannot change. C# provides this exact functionality in fact! We can slap the “readonly” keyword (and drop any setters) so that we can guarantee that our struct is now immutable.
Here’s how it looks now
public readonly struct SixteenBitStruct
{
public double D1 { get; }
public double D2 { get; }
}
Revisiting our performance numbers
Let’s re-run our benchmarks and assess the performance.
Method
limit
Mean
Error
StdDev
BenchmarkIncrementByRef
100000000
23.93 ms
0.1226 ms
0.1147 ms
BenchmarkIncrementByIn
100000000
24.06 ms
0.2183 ms
0.2042 ms
Far better! Performance is now equal (within margin of error). Some closing thoughts about this:
Using the in operator is an excellent feature – it allows the callers to safely assume that the values they are going to pass will not have their values changed.
Using the readonly modifier with a struct is another excellent feature – it allows the the developer to safely say that its value is immutable and no changes are allowed.
The performance uplift is should be considered as a bonus – the design and infrastructure wins using the in / readonly keywords in these context carry far more value.
Don’t ever use the in keyword in conjunction with non-readonly structs. Chances are that the performance gained from passing by ref will be lost by accessing the struct’s properties and methods.
In this series of posts, we’ll be investigating key areas for micro-optimizations. As the title implies, these are micro-optimizations and may not be applicable for you unless you are writing some high-performance library of have a piece of code running in a tight loop. Nonetheless, it’s still fun to investigate and find these micro-optimizations. Onwards!
Let’s start with a simple one – the ref keyword in method arguments. For this argument, we’re only concerned with value type method arguments – structs.
Since structs are value types, by default, the entire struct is copied over to the callee, irrelevant of the size of the struct. If the struct is big, this is typically a bottleneck since a copy must be created and passed for each call. C# provides a method of overriding this behavior by using the ref keyword. If an argument is marked as ref, a pointer to the struct will be passed rather than an actual copy!
This brings two major advantages:
If the struct is bigger than 4 bytes (on a 32 bit machine) or 8 bytes (on a 64 bit machine), passing a struct by ref means that less data copying is taking place.
We avoid copying back the data – we do not need to return the data since a reference is passed rather than a copy of the struct.
Let’s see an example – lets consider a struct containing two doubles – a 16 byte struct. Let’s say we have two methods that increments one of the values for us (just to give the loop something to do and not get it optimised away).
One of them accepts a (copy of a) struct, increments its internal values and returns the copy back. This is passed by value, which is the default behavior for a struct.
The other method accepts a struct by ref and increments its internal values. There is no need to return the data back therefore no extra copies were needed. This is not the default behavior, so we’ll need to accompany it with the ref keyword.
[CoreJob]
public class SixteenBytesStructBenchmark
{
[Benchmark]
[Arguments(1000000)]
public void BenchmarkIncrementByRef(int limit)
{
SixteenBytesStruct value = new SixteenBytesStruct();
int counter = 0;
do
{
IncrementByRef(ref value);
counter++;
}
while (limit != counter);
}
[Benchmark]
[Arguments(1000000)]
public void BenchmarkIncrementByVal(int limit)
{
SixteenBytesStruct value = new SixteenBytesStruct();
int counter = 0;
do
{
value = IncrementByVal(value);
counter++;
}
while (limit != counter);
}
private void IncrementByRef(ref SixteenBytesStruct toIncrement)
{
toIncrement.d0++;
}
private SixteenBytesStruct IncrementByVal(SixteenBytesStruct toIncrement)
{
toIncrement.d0++;
return toIncrement;
}
}
public struct SixteenBytesStruct
{
public long d0, d1;
}
The below is the time taken for 1000000 runs – this was executed using .NET core 2.2.1 – benchmarks done using BenchmarkDotNet
Method
limit
Mean
Error
StdDev
BenchmarkIncrementByRef
1000000
1.663 ms
0.0139 ms
0.0130 ms
BenchmarkIncrementByVal
1000000
2.872 ms
0.0155 ms
0.0145 ms
We can see that running this in a tight loop, doing the work by ref, in this case, is 72% faster! To what can we attribute this performance change? Let’s have a look at what’s happening behind the scenes.
Doing the work by value
Calling IncrementByVal
IL_000a: ldarg.0 # Load the “this” parameter on evaluation stack (implicit)
IL_000b: ldloc.0 # Load SixteenBytesStruct value on the stack (16 bytes worth of data) from location 0
IL_000c: call instance valuetype Ref.SixteenBytesStruct Ref.SixteenBytesStructBenchmark::IncrementByVal(valuetype Ref.SixteenBytesStruct) # Call IncrementByVal with the loaded arguments
IL_0011: stloc.0 #Captures the returned value and stores it in location 0
IncrementByVal Implementation
IL_0000: ldarga.s toIncrement # Load the argument’s address so processing can begin
..method work – removed for brevity
IL_001a: ldarg.1 # Load the value of the field back so it can be returned
IL_001b: ret
What’s happening here?
Push the value of SixteenBytesStruct ready to be captured by the upcoming method call
Call IncrementByVal
IncrementByVal loads the address of the received value from the caller and does the required work
Push the value of the SixteenByteStruct after the work has been done ready to be captured by the caller
IncrementByVal Returns
Pop the value from replace the value of SixteenBytesStruct with the new one
Doing the work by ref
Calling IncrementByRef
IL_000a: ldarg.0 # Load the “this” parameter on evaluation stack (implicit)
IL_000b: ldloca.s V_0 # Load SixteenBytesStruct’s address on the stack (8 bytes worth of data)
IL_000d: call instance void Ref.SixteenBytesStructBenchmark::IncrementByRef(valuetype Ref.SixteenBytesStructamp;) # Call IncrementByVal with the loaded arguments
IncrementByVal Implementation
IL_0000: ldarg.1 # Load the argument so processing can begin. We’re not calling ldarga.s since this already the struct’s address rather than the actual value
..method work – removed for brevity
IL_0018: ret # Return
What’s happening here?
Push the address of SixteenBytesStruct ready to be captured by the upcoming method call
Call IncrementByVal
IncrementByVal gets value received from the caller (the value is an address) and does the required work
IncrementByVal Returns
What does this mean?
One can obviously note that doing the work by ref has significantly less work to do:
The callee is pushing 8 bytes instead of 16 bytes
The callee loads 8 bytes onto the evaluation stack instead of 16 bytes
The callee doesn’t need to push the new value onto the evaluation stack
The callee doesn’t need to pop the stack and stored the updated value
Therefore, doing the work by ref is pushing less data when a method call takes place (maximum of 8 bytes, irrespective of the struct size) and is avoiding two data copy instructions, since it does not need to push and pop the new value since there are no return values.
If you increase the size of the struct, the performance gains would be even bigger, as shown in the below graph.
We can observe some useful information from this graph
When it comes to doing operations by ref, performance is basically equivalent all cross the board, irrelevant to the size of the struct.
16 byte, 8 byte and 4 byte structs carry identical performance – they are just separated by the margin of error.
16 byte, 8 byte and 4 byte structs are faster than 2 byte and 1 byte structs. In fact, 1 byte struct ends up clearly slower than a 2 byte struct! It’s very interesting to explore why 1 and 2 byte structs exhibit performance degradation.
The rest of the result show a consistent upward trend – which reflect the amount of data copying take place.
What’s very interesting is that a 4 byte integer operates faster by value when compared to 1 byte and 2 byte integers!
The ensure concept is a programming practice that involves calling a method called EnsureXxx() before proceeding with your method call which deals with two main usages: security and performance.
Security
Let’s start by discussing the security usage of the Ensure pattern. When you enter a piece of code that can be considered critical, one needs to make sure that the code can proceed safely. Thus, before executing any call that requires such safety, an Ensure method is called.
Typically, this method will check the state that the code is currently is running is valid (what defines valid is up to the program itself) and any properties are sanity checked. In case that the state or properties are invalid, the code will simply throw an exception and the execution is immediately stopped.
A typical signature of this method will not accept any parameter and return void, such as EnsureAccessToDatabase(). Such method will make sure that the application is in the correct state and any properties (such as the connection string) are properly set.
Performance
The second usage of the Ensure pattern is performance. Many times, creating new objects will create internal dependencies which may be expensive to create. Even worse, it might be the case that the code only makes use of a portion of such objects and ends up not using the expensive dependencies. In order to circumvent this, any performant code will delegate the creation of expensive objects until they are needed.
Let’s consider an example – let’s say we have an object that may require a database access if certain operations are executed. These certain operations would implement a call such as EnsureDatabaseConnection(), which would check if the database connection exists and opens it if it does not.
The second usage is a but obsolete nowadays though – given the introduction of the Lazy<T> class nowadays, it makes more sense to wrap your deferred instances in a Lazy<T> rather than in an Ensure method. The Lazy provides native multi-thread initialisation support which you will have to do manually in an ensure pattern.
In real world applications, I still use the security component of the pattern though; it’s a very clean way to do security and sanity checks in your code, without becoming bloated.
What do you do when you have a piece of code that can fail, and when it fails, you need to log to a database? You wrap your code in a try-catch block and chuck a Log call in the catch block. That’s all good! What if I tell you that there is a better way to do it?
try
{
// Code that might fail
}
catch(Exception ex)
{
// Handle
// Log to database
}
What’s the problem with the typical approach?
When your code enters a catch block – the stack unwinds. This refers to the process when the stack goes backwards / upwards in order to arrive the stack frame where the original call is located. Wikipedia can explain this in a bit more detail. What this means is that we might lose information with regards to the original stack location and information. If a catch block is being entered just to log to the database and then the exception is being re-thrown, this means that we’re losing vital information to discover where the issue exists; this is especially true in release / live environments.
What’s the way forward?
C# 6 offers the Exception Filtering concept; here’s how to use it.
The above catch block won’t be executed if the ErrorCode property of the exception is not greater than zero. Brilliant, we can now introduce logic without interfering with the catch mechanism and avoiding stack unwinding!
A more advanced example
Let’s now go and see a more advanced example. The application below accepts input from the Console – when the input length is zero, an exception with code 0 is raised, else an exception with code 1 is raised. Anytime an exception is raised, the application logs it. Though, the exception is only caught if only if the ErrorCode is greater than 0. The complete application is on GitHub.
class Program
{
static void Main(string[] args)
{
while (true)
{
new FancyRepository().GetCatchErrorGreaterThanZero(Console.ReadLine());
}
}
}
public class FancyRepository
{
public string GetCatchErrorGreaterThanZero(string value)
{
try
{
return GetInternal(value);
}
catch (FancyException fe) when (LogToDatabase(fe.ErrorCode) || fe.ErrorCode > 0)
{
throw;
}
}
private string GetInternal(string value)
{
if (!value.Any())
throw new FancyException(0);
throw new FancyException(1);
}
private bool LogToDatabase(int errorCode)
{
Console.WriteLine($"Exception with code {errorCode} has been logged");
return false;
}
}
1st Scenario – Triggering the filter
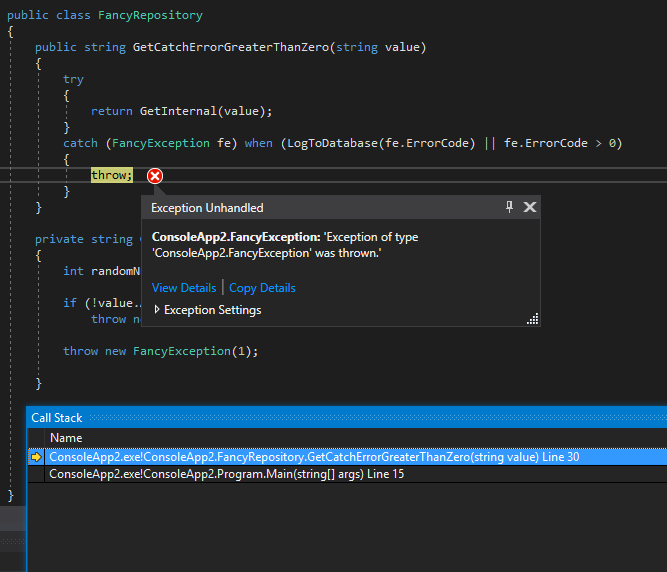
In the first scenario, when the exception is thrown by the GetInternal method, the filter successfully executes and prevents the code from entering the catch statement. This can be illustrated by the fact that Visual Studio breaks in the throw new FancyException(0); line rather than in the throw; line. This means that the stack has not been unwound; this can be proven by the fact that we can still investigate the randomNumber value. The Call Stack is fully preserved – we can go through each frame and investigate the data in each call stack.
2nd Scenario – Triggering the catch
In the second scenario, when the exception is thrown by the GetInternal method, the filter does not handle it due to the ErrorCode is greater than 0. This means that the catch statement is executed and the error is re-thrown. In the debugger, we can see this due to the fact that Visual Studio break in the throw; line rather than the throw new FancyException(1); line. This means that we’ve lost a stack frame; it is impossible to investigate the randomNumber value, since the stack has been unwound to the GetCatchErrorGreaterThanZero call.
Although the second example generates more IL (which is partly due the value checking), it does not enter the catch block! Interestingly enough the filter keyword, is not available in C# directly (only available through the use of the when keyword.
Credits
This blog post would have been impossible if readers of my blog did not provide me with the necessary feedback. I understand that the first version of this post was outright wrong. I’ve taken feedback received from my readers and changed it so now it delivers the intended message. I thank all the below people.
Rachel Farrell – Introduced me to the fact that the when keyword generates the filter IL rather than just being syntactic sugar.
Ben Camilleri – Pointed out that when catching the exception, the statement should be throw; instead of throw ex; to maintain the StackTrace property properly.
Cedric Mamo – Pointed out that the logic was flawed and provided the appropriate solution in order to successfully demonstrate it using Visual Studio.
Lately, I was working on a Windows Service using C#. Having never done such using C#, I’d thought that I’d go through the documentation that Microsoft provides. I went through it in quite a breeze; my service was running in no time.
I then added some initialisation code, which means that service startup is not instant. No problem with that; in fact the documentation has a section dedicated for such. The user’s code can provide some status update on what state the initialisation is. Unfortunately, C# does not provide this functionality; you’ll have to call native API to do so (through the SetServiceStatus call).
As I was going through the C# documentation of the struct that it accepts, I noticed that it does not match up with the documentation for the native API. The C# says that it accept long (64-bit) parameters, whilst the native API says that it accepts DWORD (32-bit) parameters. This got me thinking; is the C# documentation wrong?
I’ve whipped up two applications: one in C++ and one in C#. I checked the size of, in bytes, of the SERVICE_STATUS that SetServiceStatus expects. The answer was 28 bytes, which makes sense given that it consists of 7 DWORDs (32-bit) – 7 * 4 = 28 bytes.
The C# application consists of copying and pasting the example in Microsoft’s documentation. After checking out the ServiceStatus struct’s size, it showed 56! Again, this was not surprising, since it consists of 6 long (64-bit) plus the ServiceState enum (which defaults to int, 32-bit) plus an additional 32-bit of padding – (6 * 8) + 4 + 4 = 56 . Therefore, the resultant struct is 56 bytes instead of 28 bytes!
int size = Marshal.SizeOf(typeof(ServiceStatus));
Console.WriteLine("Size: " + size);
Unfortunately, this will still to appear to work in the code, but obviously the output of this function is undefined since the data that’s being fed in is totally out of alignment. To make matters worse, pinvoke.net reports this as Microsoft do, which threw me off in the beginning as well.
Naturally, fixing this issue is trivial; it’s just a matter of converting all longs to uint (since DWORD is an unsigned integer). Therefore, the example should look like the following:
public enum ServiceState
{
SERVICE_STOPPED = 0x00000001,
SERVICE_START_PENDING = 0x00000002,
SERVICE_STOP_PENDING = 0x00000003,
SERVICE_RUNNING = 0x00000004,
SERVICE_CONTINUE_PENDING = 0x00000005,
SERVICE_PAUSE_PENDING = 0x00000006,
SERVICE_PAUSED = 0x00000007,
}
[StructLayout(LayoutKind.Sequential)]
public struct ServiceStatus
{
public uint dwServiceType;
public ServiceState dwCurrentState;
public uint dwControlsAccepted;
public uint dwWin32ExitCode;
public uint dwServiceSpecificExitCode;
public uint dwCheckPoint;
public uint dwWaitHint;
};
The other day, I was discussing with a colleague on whether or not the usage of out parameters is OK. If I’m honest, I immediately cringed as I am not really a fan of said keyword. But first, let’s briefly discuss what on how the ‘out’ parameter keyword works.
In C#, the ‘out’ keyword is used to allow a method to return multiple values of data. This means that the method can return data using the ‘return’ statement and modify values using the ‘out’ keyword. Why did I say modify instead of return when referring to the out statement? Simple, because what the ‘out’ does, is that it receives a pointer to said data structure and then dereferences and applies the value when a new value is assigned. This means that the ‘out’ keyword is introducing the concept of pointers.
OK, the previous paragraph may not make much sense if you do not have any experience with unmanaged languages and pointers. And that’s exactly the main problem with the ‘out’ parameter. It’s introducing pointers without the user’s awareness.
Let’s now talk about the pattern and architecture of said ‘out’ parameter. As we said earlier, the ‘out’ keyword is used in a method to allow it to return multiple values. An ‘out’ parameter gives a guarantee that the value will get initialised by the callee and the callee does not expect the value passed as the out parameter to be initialised. Let’s see an example:
User GetUser(int id, out string errorMessage)
{
// User is fetched from database
// ErrorMessage is set if there was an error fetching the user
}
This may be used as such
string errorMessage;
User user = GetUser(1, out errorMessage);
By the way, C# 7 now allows the out variable to be declared inline, looking something like this:
User user = GetUser(1, out string errorMessage);
This can easily be refactored, so that the message can be returned encapsulated within the same object. It may look something like the below:
class UserWithError
{
User user {get; set;}
string ErrorMessage {get; set;}
}
UserWithError GetUser(int id)
{
// User is fetched from database
// ErrorMessage is set if there was an error fetching the user
}
Let’s quickly go through the problems with the ‘out’ keyword exposed. Firstly, it’s not easy to discard the return value. With a return value, we can easily call GetUser and ignore the return value. But with the out parameter, we do have to pass a string to capture the error message, even if one does not need the actual error message. Secondly, declaration is a bit more cumbersome since it needs to happen in more than one line (since we need to declare the out parameter). Although this was fixed in C# 7, there are a lot of code-bases which are not running C# 7. Lastly, this prevents from the method to run as “async”.
Last thing I want to mention is the use of the ‘out’ keyword in the Try pattern, which returns a bool as a return type, and sets a value using the ‘out’ keyword. This is the only globally accepted pattern which makes use of the ‘out’ keyword.
int amount;
if(Int32.TryParse(amountAsString, out amount))
{
//amountAsString was indeed an integer
}
Long story short, if you want a method to return multiple values, wrap them in a class; don’t use thee ‘out’ keyword.
If you, the reader, are like me, chances are you spend your fair share of your time programming during the weekend. It’s in us; it’s a passion. But, I believe that some of us are doing it wrong. Some people work on the same line of technologies during the weekend as they do during the week. They do not expose themselves to new technologies; always stuck with the same comfortable boundaries. It’s time to push yourself.
There is nothing wrong by doing programming during the weekend. For me, it’s an itch that needs to be scratched. Though, I try to avoid using technologies that I use at work, to expose myself to the ever changing world of programming. Sometimes, it’s not easy to expose yourself to new technologies. There are several barriers that hinder this. Here are a few.
It’s a new programming language
Chances are that if you’re trying a new technology, it’s backed up by a different programming language. This means that you’ll likely to get stuck in very trivial problems, such simply forgetting syntax or lacking the knowledge of the underlying APIs. You’ll end up re-implementing features that probably already exist and provided natively by the language’s supporting libraries. That’s OK though, you’ll likely to end up Google-ing problems whilst doing so, and learning new techniques whilst doing so.
It’s a new programming paradigm
This is a bit tougher. You’ll be leaving the typical train of thought that you usually think with. A typical example is a C# / Java developer having a crack at some C programming. Although C# / Java are indeed influenced by C, they live in a separate programming paradigm. C# / Java are object-oriented languages, whilst C is a procedural language. You’ll need to think quite differently when programming in these languages.
It’s a different programming genertion
This is similar to the point above, but simply different classification. One might work a lot with 3GL languages, such as C# / Java / C or your typical run-off-the-mill language. You want to have a crack at some good SQL. It’s a different programming generation on it’s own. The definition might be a bit stumped, but the differences certainly exist. 3GL languages deal with general-purpose langues and 4GL deal with table structures. One is not meant to replace the other; they are simply complementing each other.
It’s a different application type
Most of us developers normally work targeting a type of application such as Web Applications or desktop applications. Designing an application to target any one of these types require a very different train of thought. Writing a desktop application? You need to think about having a fluid experience, whist probably being fairly portable. Writing a web application? It needs to work across browsers and different types of clients. Each of these applications require a very different tool-set (and potentially, programming language). Also, even if you’re targeting the same type of applications, there are very different types of solutions that lie in the same application paradigm.
It’s a different approach of the same application type
If I’m honest, I could not come up with an appropriate title for this category. I’ll try to explain. Let’s consider the desktop programming side for this category. There are numerous different applications that live in the application type. These are: your typical desktop application, a background service / daemon, a 3D application, a driver, you name it! For each type of desktop application, a very different tools and skillset is required.
What can we conclude from these previous points? We can see that there are loads of different areas that as programmers, we have probably never experimented with. If you pick one of the points that I mentioned above and apply it to your weekend programming, it will be a totally new experience for you.
Where can one start? Well, it’s easy! One can apply one of the different approaches that I just mentioned above and take it to Google / YouTube! You can also experiment with other premium providers such as Pluralsight and such. These paid platforms do not come cheap, but most of their content come from very reputable people and provide excellent material to learn.
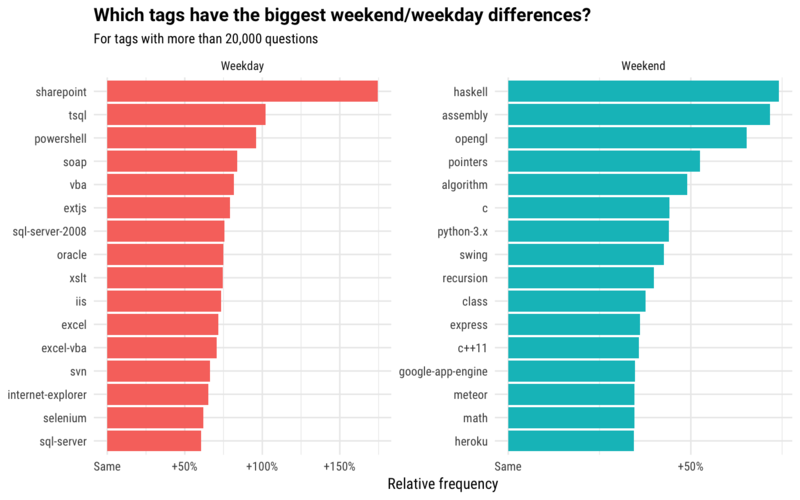
Am I the only guy who says this? No, and most of the people are sticking with this trend. An article from StackOverflow illustrate my points mentioned above, basically they checked what people are searching for during the week, and compared them to the results people are searching during the weekend. One can see that for example, SharePoint is clearly a topic that is only worked on during the weekend and Haskell is a weekend project! Check the full article here.
What’s in it for you in the end of the day? Let’s highlight some points.
Expand your professional career.
Getting stuck in the same technologies over and over again is obviously not helping you expanding your career. Your CV will never grow; it’ll just show that you’ve stuck in the same comfortable zone forever, showing that you’re probably not willing to step out of your comfort zone. On the other hand, showing experiences in vast areas show that you are never tired of learning, always up for a new challenge and you can step out of your comfort zone.
Gather new skills.
Sometimes seeing different languages, tutorials or simply different approaches to solving different tasks will enrich your mind. Even if you capture a single skill from a weekend’s worth of development, it makes you a better developer.
Gain a new outlook.
Sometimes, you’re stuck thinking that your way is the only way, or the best way to solve a task. Then, you’re following a new technique in a completely different language or paradigm and realise that there exists a totally different solution to your everyday task that you can apply.
Contribute to the community.
We’ve all used projects that have been written by the community, for the community. Have you ever contributed back If you’re stuck with the same skill-set, probably not. Learning new stuff will enable you to do just so. Plus the satisfaction of giving back the community is simply a great feeling.
Have fun!
Last, and probably the most important, is having fun! Doing something that you don’t love doing so is pointless. This is work that you may never get to use in your professional life it’s just work that needs to get your programming juices flowing and enjoying oneself learning and experimenting with new things.