What do you do when you have a piece of code that can fail, and when it fails, you need to log to a database? You wrap your code in a try-catch block and chuck a Log call in the catch block. That’s all good! What if I tell you that there is a better way to do it?
try
{
// Code that might fail
}
catch(Exception ex)
{
// Handle
// Log to database
}
What’s the problem with the typical approach?
When your code enters a catch block – the stack unwinds. This refers to the process when the stack goes backwards / upwards in order to arrive the stack frame where the original call is located. Wikipedia can explain this in a bit more detail. What this means is that we might lose information with regards to the original stack location and information. If a catch block is being entered just to log to the database and then the exception is being re-thrown, this means that we’re losing vital information to discover where the issue exists; this is especially true in release / live environments.
What’s the way forward?
C# 6 offers the Exception Filtering concept; here’s how to use it.
try
{
//Code
}
catch (FancyException fe) when (fe.ErrorCode > 0)
{
//Handle
}
The above catch block won’t be executed if the ErrorCode property of the exception is not greater than zero. Brilliant, we can now introduce logic without interfering with the catch mechanism and avoiding stack unwinding!
A more advanced example
Let’s now go and see a more advanced example. The application below accepts input from the Console – when the input length is zero, an exception with code 0 is raised, else an exception with code 1 is raised. Anytime an exception is raised, the application logs it. Though, the exception is only caught if only if the ErrorCode is greater than 0. The complete application is on GitHub.
class Program
{
static void Main(string[] args)
{
while (true)
{
new FancyRepository().GetCatchErrorGreaterThanZero(Console.ReadLine());
}
}
}
public class FancyRepository
{
public string GetCatchErrorGreaterThanZero(string value)
{
try
{
return GetInternal(value);
}
catch (FancyException fe) when (LogToDatabase(fe.ErrorCode) || fe.ErrorCode > 0)
{
throw;
}
}
private string GetInternal(string value)
{
if (!value.Any())
throw new FancyException(0);
throw new FancyException(1);
}
private bool LogToDatabase(int errorCode)
{
Console.WriteLine($"Exception with code {errorCode} has been logged");
return false;
}
}
1st Scenario – Triggering the filter
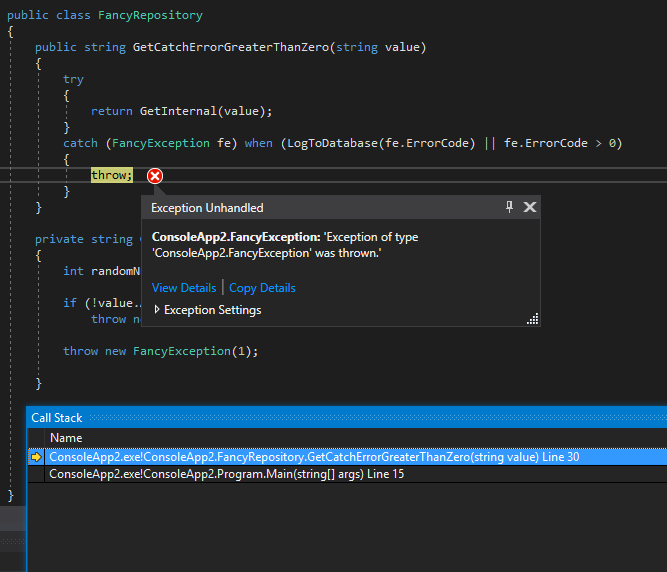
In the first scenario, when the exception is thrown by the GetInternal method, the filter successfully executes and prevents the code from entering the catch statement. This can be illustrated by the fact that Visual Studio breaks in the throw new FancyException(0); line rather than in the throw; line. This means that the stack has not been unwound; this can be proven by the fact that we can still investigate the randomNumber value. The Call Stack is fully preserved – we can go through each frame and investigate the data in each call stack.

2nd Scenario – Triggering the catch
In the second scenario, when the exception is thrown by the GetInternal method, the filter does not handle it due to the ErrorCode is greater than 0. This means that the catch statement is executed and the error is re-thrown. In the debugger, we can see this due to the fact that Visual Studio break in the throw; line rather than the throw new FancyException(1); line. This means that we’ve lost a stack frame; it is impossible to investigate the randomNumber value, since the stack has been unwound to the GetCatchErrorGreaterThanZero call.
What’s happening under the hood?
As one can assume, the underlying code being generated must differ at an IL level, since the stack is not being unwound. And one would assume right – the when keyword is being translated into the filter instruction.
Let’s take two try-catch blocks, and see their equivalent IL.
try
{
throw new Exception();
}
catch(Exception ex)
{
}
Generates
.try
{
IL_0003: nop
IL_0004: newobj instance void [mscorlib]System.Exception::.ctor()
IL_0009: throw
} // end .try
catch [mscorlib]System.Exception
{
IL_000a: stloc.1
IL_000b: nop
IL_000c: nop
IL_000d: leave.s IL_000f
} // end handler
The next one is just like the previous, but it introduces a filter to check on some value on whether it’s equivalent to 1.
try
{
throw new Exception();
}
catch(Exception ex) when(value == 1)
{
}
Generates
.try
{
IL_0010: nop
IL_0011: newobj instance void [mscorlib]System.Exception::.ctor()
IL_0016: throw
} // end .try
filter
{
IL_0017: isinst [mscorlib]System.Exception
IL_001c: dup
IL_001d: brtrue.s IL_0023
IL_001f: pop
IL_0020: ldc.i4.0
IL_0021: br.s IL_002d
IL_0023: stloc.2
IL_0024: ldloc.0
IL_0025: ldc.i4.1
IL_0026: ceq
IL_0028: stloc.3
IL_0029: ldloc.3
IL_002a: ldc.i4.0
IL_002b: cgt.un
IL_002d: endfilter
} // end filter
{ // handler
IL_002f: pop
IL_0030: nop
IL_0031: nop
IL_0032: leave.s IL_0034
} // end handler
Although the second example generates more IL (which is partly due the value checking), it does not enter the catch block! Interestingly enough the filter keyword, is not available in C# directly (only available through the use of the when keyword.
Credits
This blog post would have been impossible if readers of my blog did not provide me with the necessary feedback. I understand that the first version of this post was outright wrong. I’ve taken feedback received from my readers and changed it so now it delivers the intended message. I thank all the below people.
Rachel Farrell – Introduced me to the fact that the when keyword generates the filter IL rather than just being syntactic sugar.
Ben Camilleri – Pointed out that when catching the exception, the statement should be throw; instead of throw ex; to maintain the StackTrace property properly.
Cedric Mamo – Pointed out that the logic was flawed and provided the appropriate solution in order to successfully demonstrate it using Visual Studio.
Until the next one!






