In this series of posts, we’ll be investigating key areas for micro-optimizations. As the title implies, these are micro-optimizations and may not be applicable for you unless you are writing some high-performance library of have a piece of code running in a tight loop. Nonetheless, it’s still fun to investigate and find these micro-optimizations. Onwards!
Let’s start with a simple one – the ref keyword in method arguments. For this argument, we’re only concerned with value type method arguments – structs.
Since structs are value types, by default, the entire struct is copied over to the callee, irrelevant of the size of the struct. If the struct is big, this is typically a bottleneck since a copy must be created and passed for each call. C# provides a method of overriding this behavior by using the ref keyword. If an argument is marked as ref, a pointer to the struct will be passed rather than an actual copy!
This brings two major advantages:
- If the struct is bigger than 4 bytes (on a 32 bit machine) or 8 bytes (on a 64 bit machine), passing a struct by ref means that less data copying is taking place.
- We avoid copying back the data – we do not need to return the data since a reference is passed rather than a copy of the struct.
Let’s see an example – lets consider a struct containing two doubles – a 16 byte struct. Let’s say we have two methods that increments one of the values for us (just to give the loop something to do and not get it optimised away).
One of them accepts a (copy of a) struct, increments its internal values and returns the copy back. This is passed by value, which is the default behavior for a struct.
The other method accepts a struct by ref and increments its internal values. There is no need to return the data back therefore no extra copies were needed. This is not the default behavior, so we’ll need to accompany it with the ref keyword.
The below is the source code in question – find the whole solution here: https://github.com/albertherd/csharpmopt1-ref
[CoreJob]
public class SixteenBytesStructBenchmark
{
[Benchmark]
[Arguments(1000000)]
public void BenchmarkIncrementByRef(int limit)
{
SixteenBytesStruct value = new SixteenBytesStruct();
int counter = 0;
do
{
IncrementByRef(ref value);
counter++;
}
while (limit != counter);
}
[Benchmark]
[Arguments(1000000)]
public void BenchmarkIncrementByVal(int limit)
{
SixteenBytesStruct value = new SixteenBytesStruct();
int counter = 0;
do
{
value = IncrementByVal(value);
counter++;
}
while (limit != counter);
}
private void IncrementByRef(ref SixteenBytesStruct toIncrement)
{
toIncrement.d0++;
}
private SixteenBytesStruct IncrementByVal(SixteenBytesStruct toIncrement)
{
toIncrement.d0++;
return toIncrement;
}
}
public struct SixteenBytesStruct
{
public long d0, d1;
}
The below is the time taken for 1000000 runs – this was executed using .NET core 2.2.1 – benchmarks done using BenchmarkDotNet
| Method | limit | Mean | Error | StdDev |
|---|---|---|---|---|
| BenchmarkIncrementByRef | 1000000 | 1.663 ms | 0.0139 ms | 0.0130 ms |
| BenchmarkIncrementByVal | 1000000 | 2.872 ms | 0.0155 ms | 0.0145 ms |
We can see that running this in a tight loop, doing the work by ref, in this case, is 72% faster! To what can we attribute this performance change? Let’s have a look at what’s happening behind the scenes.
Doing the work by value
Calling IncrementByVal
IL_000a: ldarg.0 # Load the “this” parameter on evaluation stack (implicit) IL_000b: ldloc.0 # Load SixteenBytesStruct value on the stack (16 bytes worth of data) from location 0 IL_000c: call instance valuetype Ref.SixteenBytesStruct Ref.SixteenBytesStructBenchmark::IncrementByVal(valuetype Ref.SixteenBytesStruct) # Call IncrementByVal with the loaded arguments IL_0011: stloc.0 #Captures the returned value and stores it in location 0
IncrementByVal Implementation
IL_0000: ldarga.s toIncrement # Load the argument’s address so processing can begin ..method work – removed for brevity IL_001a: ldarg.1 # Load the value of the field back so it can be returned IL_001b: ret
What’s happening here?
- Push the value of SixteenBytesStruct ready to be captured by the upcoming method call
- Call IncrementByVal
- IncrementByVal loads the address of the received value from the caller and does the required work
- Push the value of the SixteenByteStruct after the work has been done ready to be captured by the caller
- IncrementByVal Returns
- Pop the value from replace the value of SixteenBytesStruct with the new one
Doing the work by ref
Calling IncrementByRef
IL_000a: ldarg.0 # Load the “this” parameter on evaluation stack (implicit) IL_000b: ldloca.s V_0 # Load SixteenBytesStruct’s address on the stack (8 bytes worth of data) IL_000d: call instance void Ref.SixteenBytesStructBenchmark::IncrementByRef(valuetype Ref.SixteenBytesStructamp;) # Call IncrementByVal with the loaded arguments
IncrementByVal Implementation
IL_0000: ldarg.1 # Load the argument so processing can begin. We’re not calling ldarga.s since this already the struct’s address rather than the actual value ..method work – removed for brevity IL_0018: ret # Return
What’s happening here?
- Push the address of SixteenBytesStruct ready to be captured by the upcoming method call
- Call IncrementByVal
- IncrementByVal gets value received from the caller (the value is an address) and does the required work
- IncrementByVal Returns
What does this mean?
One can obviously note that doing the work by ref has significantly less work to do:
- The callee is pushing 8 bytes instead of 16 bytes
- The callee loads 8 bytes onto the evaluation stack instead of 16 bytes
- The callee doesn’t need to push the new value onto the evaluation stack
- The callee doesn’t need to pop the stack and stored the updated value
Therefore, doing the work by ref is pushing less data when a method call takes place (maximum of 8 bytes, irrespective of the struct size) and is avoiding two data copy instructions, since it does not need to push and pop the new value since there are no return values.
If you increase the size of the struct, the performance gains would be even bigger, as shown in the below graph.
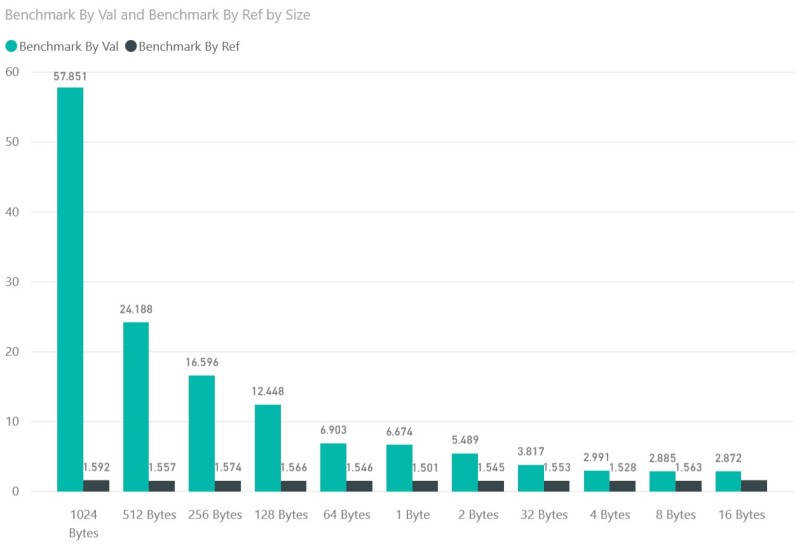
We can observe some useful information from this graph
- When it comes to doing operations by ref, performance is basically equivalent all cross the board, irrelevant to the size of the struct.
- 16 byte, 8 byte and 4 byte structs carry identical performance – they are just separated by the margin of error.
- 16 byte, 8 byte and 4 byte structs are faster than 2 byte and 1 byte structs. In fact, 1 byte struct ends up clearly slower than a 2 byte struct! It’s very interesting to explore why 1 and 2 byte structs exhibit performance degradation.
- The rest of the result show a consistent upward trend – which reflect the amount of data copying take place.
What’s very interesting is that a 4 byte integer operates faster by value when compared to 1 byte and 2 byte integers!

We can observe some useful information from this graph
When it comes to doing operations “by value’, performance is basically
by ref?
LikeLike
Fixed, thanks!
LikeLike